
Zhruba před rokem jsem psala, že Google Dokumenty umí OCR, ale nezvládají češtinu. Článek na http://www.freetech4teachers.com o konverzi pdf na textový dokument mi OCR zase připomenul. A tak jsem zkusila předhodit Google Dokumentům pár obrázků plných textu, abych otestovala češtinu a ono to funguje! Ale hodně záleží na konkrétním textu a kvalitě obrázku, chce to prostě vyzkoušet.
-
- Otevření v GD
-
- Vložený obrázek
-

- Převedený text
Jak na to?
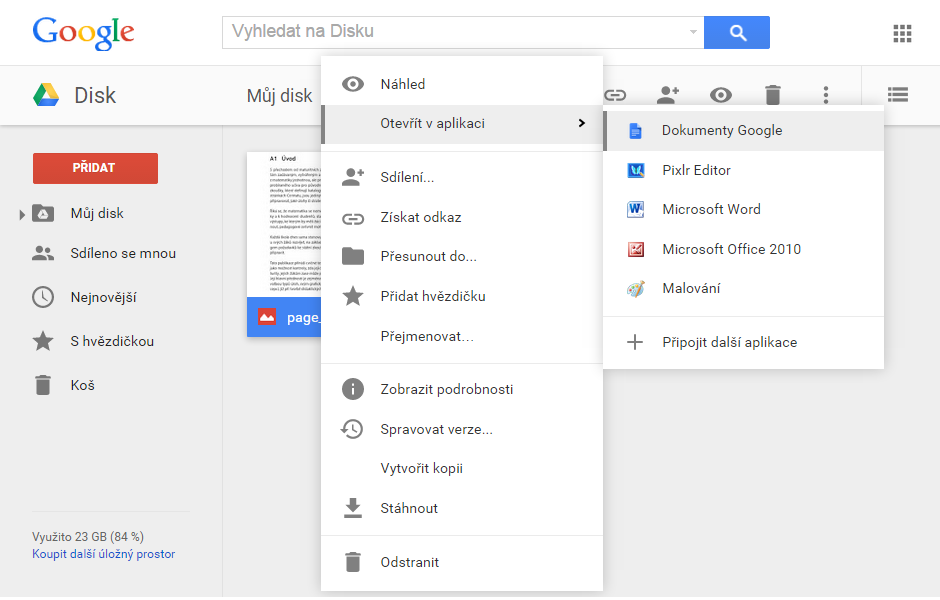
- obrázek neotvírejte, ale vyberte z menu Otevřít v aplikaci > Google Dokumenty
- chvíle chroustáni a napětí 🙂
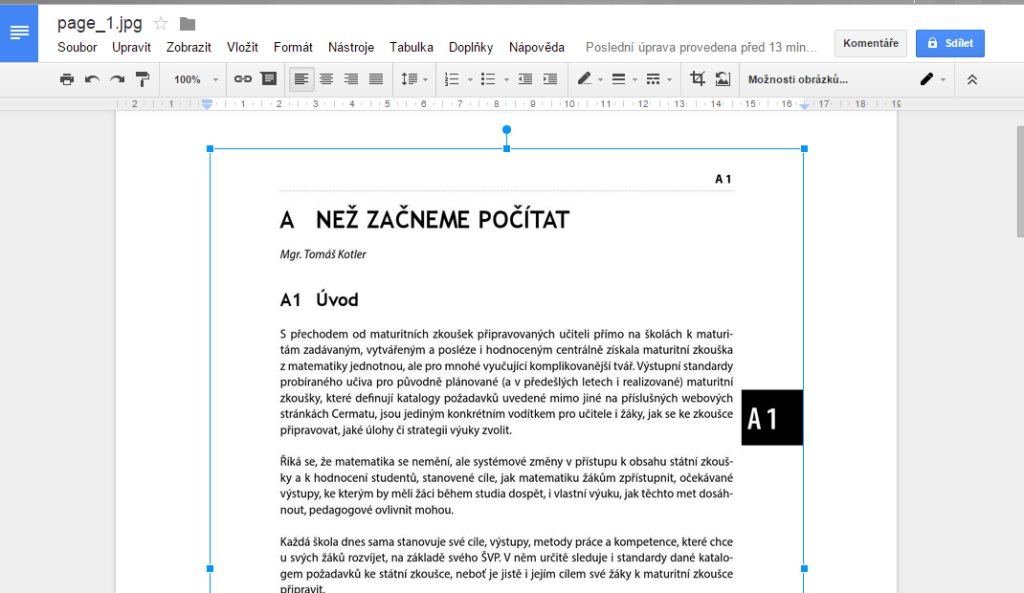
- získáte dokument, kde na úvod je vložený obrázek a pod ním již máte text.